

Helping you with Process mining, IoT and data
Wszyscy chcemy je optymalizować i zautomatyzować, ale…
Wyobraźmy sobie proces realizacji zamówienia, ale od samego początku, czyli od pierwszej komunikacji marketingowej do przyszłego klienta. Historia przebiega następująco.
Potencjalny klient trafia do naszej bazy. Wysyłamy pierwszą wiadomość marketingową, potem następną i pewnie kolejną. Klient odwiedza naszą stronę raz, może kilka razy. W końcu decyduje się na wstępną rozmowę, negocjacje i podpisanie umowy. Zauważmy, że dla większości z tych zdarzeń mamy zapis, czy to w systemie IT, czy też wiadomości email. I wyobraźmy sobie na razie, że gromadzenie wszystkich tych danych i zebranie ich w jedno miejsce nie stanowi problemu.
Idąc dalej, zamówienie jest przetwarzane wewnątrz firmy, zaczynamy proces produkcji przemysłowej albo realizacji usługi. Informacje o poszczególnych krokach cały czas trafiają np. do logów systemów IT. Z początku wszystko idzie sprawnie, ale w pewnym momencie zaczynają się opóźnienia. Nasi poddostawcy dają ciała w kwestii terminów i jakości. Nasz zespół nie radzi sobie ze zmianami jakie chce klient. Marże znikają niczym smakowity kąsek pochłaniany przez partnera na obiedzie biznesowym. Istna katastrofa.
Ale jak to w biznesie. Jesteśmy elastyczni; świat się nie kończy; z satysfakcją udaje się obronić marże i dowieźć wszystko do szczęśliwego finału. Klient dostaje rezultaty prac lub wręcz pudełko z produktem.
A teraz wyobraźmy sobie kilkadziesiąt albo kilkaset tysięcy takich historyjek, czyli pojedynczych wykonań procesu.
A można też zajrzeć głębiej – na fragmenty tej układanki. Zobaczymy wtedy, albo też usłyszymy szereg działań (podprocesów) związanych z księgowaniem dokumentów, obsługą zamówień w systemach CRM i ERP, czy ścieżką naszego klienta online.
I tutaj pojawia się pytanie, czy my tak naprawdę wiemy co tam się dokładnie po drodze w tych procesach dzieje i kiedy? Jeśli się nad tym zastanowić – to niekoniecznie. Z perspektywy 10 Senses i na podstawie naszego doświadczenia w pracy z danymi, i procesami, nasuwają się trzy spostrzeżenia:
- Procesy biznesowe potrafią żyć własnym życiem (wiem truizm, ale w tym kontekście istotny)
- Nie zawsze są zdefiniowane
- Praktycznie nigdy nie są mierzone i wizualizowane w oparciu o dane
Często intuicyjnie wiemy, że proces nie działa efektywnie i w związku z tym chcielibyśmy go zoptymalizować. Możliwe, że jesteśmy nawet w trochę lepszej sytuacji i mamy już kilka miar, które nam o tej nieefektywności mówią. Albo wręcz chodzi nam po głowie inicjatywa automatyzacji RPA, RDA, IPA (nie mylić z piwem) lub inny ciekawy skrót.
Ale zanim ruszymy z impetem do walki z nieefektywnościami czy do biczowania robotów, to warto przemyśleć kilka kwestii. Ciężko jest optymalizować albo wręcz automatyzować proces, gdy:
- nie wiemy jak on dokładnie wygląda,
- nie wiemy tak naprawdę, czy ten proces nie zmienia się w czasie,
- nie mamy łatwo porównywalnych miar opisujących ten proces.
Wyniki jednego z badań EY 1 sugerują, że 30% do 50% inicjatyw RPA początkowo kończy się porażką. Jednym z powodów okazuje się być właśnie niedostateczne zrozumienie procesów biznesowych.
A poniżej warty do rozważenia cytat:
“People are trying to apply RPA before they really know how their processes work”
Antony Edwards, COO Eggplant

Photo by Shunsuke Ono on Unsplash
Wyobraźmy sobie teraz, że możemy…
…automatycznie odkryć, jak wygląda taki proces. Zobaczyć jego diagram tylko na podstawie zapisanych danych. I na razie wyobraźmy sobie magiczną czarną skrzynkę, która te dane przetworzy. Działałoby to następująco: wrzucamy dane z różnych systemów do tej czarnej skrzynki z pokrętłami, czyli do algorytmu Process Mining, a w rezultacie dostajemy wizualizacje procesu z naniesionymi statystykami.

Wyobraźmy sobie dalej, że ten zwizualizowany proces oglądamy z różnych stron. Możemy w trakcie tych manipulacji zmieniać dynamicznie szczegółowość diagramów. Możemy zidentyfikować najczęstsze ścieżki i ewentualne odchylenia. W rezultacie możemy ocenić czy proces, a może tylko jego elementy nadają się do automatyzacji.
A gdyby tak jeszcze dało się:
- wykryć wąskie gardła w procesach i przeprowadzić analizę przyczyn źródłowych,
- znaleźć nadmiarowe czynności, które niekoniecznie potrzebujemy w tym procesie,
- zobaczyć i zmierzyć, jak współpracują ze sobą zespoły albo poszczególne osoby,
- analizować i mierzyć współpracę z dostawcami.
W rezultacie dostajemy świetny materiał do komunikacji zarówno wewnątrz zespołu jak i na zewnątrz. O ile łatwiej jest rozumieć proces patrząc na jego uproszczony diagram niż głowić się jak opisać go słowami, czy to mówionymi, czy pisanymi, czy nawet samemu taki diagram narysować. Kto próbował, to wie, że rysowanie diagramu z początku zawsze wydaje się łatwiejsze niż jest w rzeczywistości. Niby wydaje nam się, że znamy proces, a potem okazuje się, że ilość ścieżek, wariantów czy warunków rośnie i rośnie. A tutaj mamy narzędzie do automatycznego generowania takich diagramów i jeszcze potem do porównania z naszym idealnym wyobrażeniem tego procesu.
Czy nie będzie właśnie tak, że gdy pracownicy naocznie zobaczą, że wykonywane przez nich zadania są częścią większego procesu i wręcz wpływają na pracę innych, to nie będą wtedy bardziej zmotywowani, bardziej dokładni, bardziej efektywni?

Photo by Kunj Parekh on Unsplash
Dane są na wyciągnięcie ręki
Większość danych potrzebnych do zastosowania Process Mining mamy tuż pod nosem. W firmach roi się od różnego rodzaju logów, prawie wszędzie mamy do tej informacji dołączoną datę i godzinę, nierzadko też informację o tym, kto był wykonawcą, a kto odbiorcą danego zdarzenia. Rola takich danych w biznesie rośnie praktycznie z miesiąca na miesiąc. O stopniu wykorzystania Big Data w polskich przedsiębiorstwach pisaliśmy np. na naszym blogu tutaj: „Jak wygląda stan wykorzystania big data w polskich firmach?”. Jako dygresja – gorąco zachęcam do przeczytania tego raportu.
A wracając do źródeł danych, z których możemy skorzystać są to np.:
- dane w systemach CRM, ERP
- różnego rodzaju logi systemów, logi z API i urządzeń
- różnego rodzaju spisy wykonanych prac
- emaile z korespondencją, czy to z klientem czy to wewnątrz organizacji
- nagrania wideo lub audio, zrzuty ekranu, transkrypcje spotkań
Trzeba je tylko odpowiednio przetworzyć do postaci logu zdarzeń i wrzucić do maszynerii Process Mining. Oczywiście logi te mogą być niepełne, albo wymagać konkretnych przekształceń, ale to jest już temat na inny, obszerniejszy artykuł o poziomie dojrzałości dzienników zdarzeń lub szerzej o dojrzałości cyfrowej w firmach.

Photo by Isaac Davis on Unsplash
Jak to działa? (Odkrywanie procesu – jeszcze bez wnikania w technikalia)
Skupię się teraz na pierwszym efekcie jaki możemy osiągnąć, a mianowicie na automatycznym odkrywaniu procesu. Faktycznych analiz, które możemy wykonać jest znacznie więcej, ale nie starczyłoby czasu na omówienie ich wszystkich w jednym artykule.
Czego potrzebujemy? Tak naprawdę niewiele. Do pierwszego kroku wystarczy nam tabela z trzema kolumnami:
- nazwa zdarzenia,
- czas wykonania
- identyfikator instancji procesu (czyli możliwość przypisania zdarzenia do pojedynczej historyjki)
Weźmy teraz pod uwagę, że nie karmimy algorytmów, żadnymi założeniami dotyczącymi samego procesu, a dostajemy przetrawiony efekt w postaci czytelnego diagramu, bez konieczności inwestowania znacznych sił i czasu. Poniżej przykładowy diagram procesu odkrytego w całości automatycznie, wraz z możliwością analizy jego wariantów.
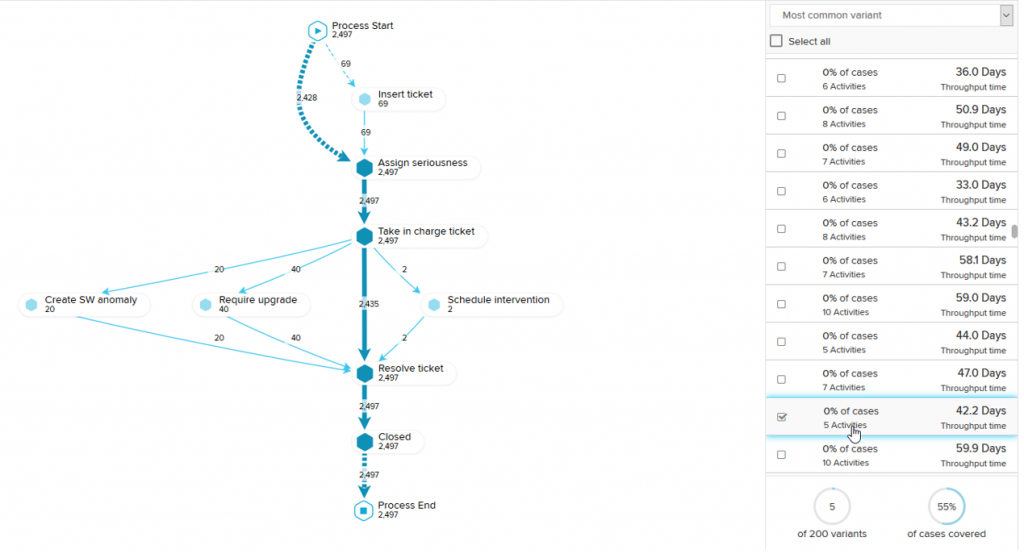
Dzięki tego typu wizualizacjom jesteśmy w stanie:
- zobaczyć warianty (czyli różne ścieżki realizacji procesu), również te nieprzewidziane w modelowym procesie,
- zidentyfikować warianty procesu, które trwają zbyt długo lub gdzie wykonywane są nadmiarowe prace
- zidentyfikować wąskie gardła.
Jeśli dorzucimy do tego informację, kto wykonywał dane zdarzenie, to bardzo szybko możemy zwizualizować kolejną paczkę informacji. Na przykład diagram procesu w kontekście tego, jak praca przechodziła z rąk do rąk.
Poniżej diagramy tego samego procesu. Z lewej ilość przekazań pracy pomiędzy użytkownikami. Z prawej czas przekazań pracy.
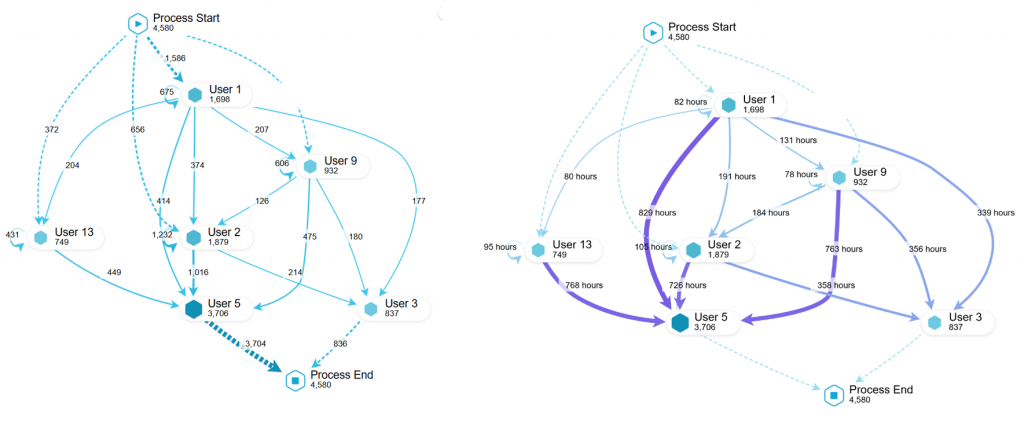
Co możemy zobaczyć dzięki przypisaniu konkretnych wykonawców do kroków w procesie? Między innymi poniższe rzeczy:
- Czas realizacji prac poszczególnych zespołów, pracowników
- Identyfikacja zespołów i osób, które generują największe opóźnienia
- Identyfikacja zespołów i osób, które wykonują niepotrzebne kroki w procesie
Oczywiście mógłbym się teraz rozpisać na temat samych algorytmów Process Mining i kolejnych analiz, ale z dużym prawdopodobieństwem zanudziłbym większość czytelników. Możliwe, że popełnię też kiedyś i taki bardziej techniczny artykuł.

Photo by Sharon McCutcheon on Unsplash
Co dalej z Process Mining?
A co, jeśli zaprzęgniemy do Process Mining również narzędzia znane z dziedzin maszynowego uczenia i sztucznej inteligencji? Standardowo w tych metodach patrzymy jakby na migawkę w czasie. Często rozważamy problem w kategoriach co mamy na wejściu do modelu ML i tego co taki model generuje na wyjściu. Sam proces, jego trwanie w czasie oraz jego niuanse nie są brane pod uwagę.
Te dwa światy można ze sobą połączyć i wtedy otwierają się całkiem nowe możliwości. Możemy np. dużo precyzyjniej prognozować wykonanie w oparciu o dane historyczne i obecne z całego procesu i na każdym jego etapie. Możemy brać pod uwagę szerszy kontekst jak dostępność zasobów, sezonowość czy efektywność współpracy poszczególnych zespołów.
Ostatnio bardzo ciekawą funkcjonalnością, którą wdraża coraz więcej nowych platform do Process Mining jest Task Mining, czyli analiza manualnych czynności, które umykają zwykle zapisom w systemach IT. Oprogramowanie zapisuje zrzuty ekranu podczas pracy użytkowników. Obrazy są analizowane za pomocą algorytmów SI i przypisywane są im niskopoziomowe cechy, jak tekst na ekranie, używany program, czas wykonania. Pojawiają się tu oczywiście kwestie prywatności, ale faktycznie platformy zapewniają ochronę również w tej kwestii. W kolejnym kroku te niskopoziomowe informacje przypisywane są do zrozumiałych biznesowo grup i finalnie jesteśmy w stanie analizować proces w zakresie dotąd niedostępnym.
—
W naszej ocenie, jeśli podejmujemy się optymalizacji czy też automatyzacji procesów w firmie, trzeba myśleć również o włączeniu do tego narzędzi Process Mining. Bez tego ryzykujemy, że niedostateczna znajomość procesów zmniejszy ROI z tych projektów.
A przecież wszyscy chcemy, żeby prace przebiegały sprawnie, a nasze inwestycje były jak najbardziej zyskowne. Warto wiedzieć jakie możliwości daje w tej kwestii Process Mining.
Helping you with Process mining, IoT and data
Chcesz przeczytać więcej o Process Mining? Zobacz artykuł:
Co to jest process mining?
Dlaczego warto korzystać z process mining?
Poniżej jeszcze kilka użytecznych informacji i źródeł…
Lista wybranych narzędzi, bibliotek, platform
Narzędzia darmowe i Open Source:
- Apromore – Community Edition
- ProM
- Celonis Snap
Komercyjne narzędzia, które powstały jako dedykowane platformy do Process Mining:
- Fluxicon Disco
- Pafnow
- Celonis
- minit
- myInvenio
- Apromore – Enterprise Edition
Narzędzia z obszaru BPMS lub RPA, które wprowadziły Process Mining do oferty:
- QPR
- Signavio
- UiPath – w październiku 2019 UiPath wykupiło ProcessGold dołączając Process Mining do narzędzi RPA
Biblioteki Python i R:
- PM4Py – https://pm4py.fit.fraunhofer.de/
- bupaR – https://www.bupar.net/
Użyteczne linki:
- processmining.org – strona o Process Mining prowadzona przez Process Mining Group z Eindhoven University of Technology
- https://www.tf-pm.org/ – IEEE Task Force on Process Mining
- https://www.fluxicon.com/blog/ – m.in. nagrania wideo z wydarzeń Process Mining Camp
- http://procesowcy.pl/dojrzalosc-procesowa-2016/ – raport o dojrzałości procesowej polskich organizacji
- https://www.kti.ue.poznan.pl/eksploracja.procesow – materiały i badania z dziedziny Process Mining przygotowane przez Katedrę Technologii Informacyjnych Uniwersytet Ekonomiczny w Poznaniu
Publikacje:
- „Process Mining Manifesto”. IEEE Task Force on Process Mining.
- (wersja oryginalna), url: http://dx.doi.org/10.1007/978-3-642-28108-2_19
- (wersja polska), url: https://www.win.tue.nl/ieeetfpm/lib/exe/fetch.php?media=shared:pmm-polish-v1.pdf
- „Process Mining – Data Science in Action”, Wil van der Aalst (2016) url: https://doi.org/10.1007/978-3-662-49851-4_1
- „What Process Mining Is, and Why Companies Should Do It”. Thomas H. Davenport, Andrew Spanyi (2019), url: https://hbr.org/2019/04/what-process-mining-is-and-why-companies-should-do-it
- „Process Mining and Robotic Process Automation: A Perfect Match”. Geyer-Klingeberg, Jerome & Nakladal, Janina & Baldauf, Fabian & Veit, Fabian. (2018). url: https://www.researchgate.net/publication/326466901_Process_Mining_and_Robotic_Process_Automation_A_Perfect_Match
Źródła danych:
Featured photo by Bart van Dijk on Unsplash
Link do badania EY:
- Chris Lamberton, “Get ready for Robotic Process Automation” 2017. [Online]. url: https://www.ey.com/gl/en/industries/financial-services/fso-insights-get-ready-for-robotic-process-automation.